15 KiB
Fast directory listing
In order to find untracked files in a git repository, gitstatusd needs to list the contents of every directory. gitstatusd does it 27% faster than a reasonable implementation that a seasoned C/C++ practitioner might write. This document explains the optimizations that went into it. As directory listing is a common operation, many other projects can benefit from applying these optimizations.
v1
Given a path to a directory, ListDir() must produce the list of files in that directory. Moreover,
the list must be sorted lexicographically to enable fast comparison with Git index.
The following C++ implementation gets the job done. For simplicity, it returns an empty list on error.
vector<string> ListDir(const char* dirname) {
vector<string> entries;
if (DIR* dir = opendir(dirname)) {
while (struct dirent* ent = (errno = 0, readdir(dir))) {
if (!Dots(ent->d_name)) entries.push_back(ent->d_name);
}
if (errno) entries.clear();
sort(entries.begin(), entries.end());
closedir(dir);
}
return entries;
}
Every directory has entries "." and "..", which we aren't interested in. We filter them out with
a helper function Dots().
bool Dots(const char* s) { return s[0] == '.' && (!s[1] || (s[1] == '.' && !s[2])); }
To check how fast ListDir() performs, we can run it many times on a typical directory. One million
runs on a directory with 32 files with 16-character names takes 12.7 seconds.
v2
Experienced C++ practitioners will scoff at our implementation of ListDir(). If it's meant to be
efficient, returning vector<string> is an unaffordable convenience. To avoid heap allocations we
can use a simple arena that will allow us to reuse memory between different ListDir() calls.
(Changed and added lines are marked with comments.)
void ListDir(const char* dirname, string& arena, vector<char*>& entries) { // +
entries.clear(); // +
if (DIR* dir = opendir(dirname)) {
arena.clear(); // +
while (struct dirent* ent = (errno = 0, readdir(dir))) {
if (!Dots(ent->d_name)) {
entries.push_back(reinterpret_cast<char*>(arena.size())); // +
arena.append(ent->d_name, strlen(ent->d_name) + 1); // +
}
}
if (errno) entries.clear();
for (char*& p : entries) p = &arena[reinterpret_cast<size_t>(p)]; // +
sort(entries.begin(), entries.end(), // +
[](const char* a, const char* b) { return strcmp(a, b) < 0; }); // +
closedir(dir);
}
}
To make performance comparison easier, we can normalize them relative to the baseline. v1 will get performance score of 100. A twice-as-fast alternative will be 200.
| version | optimization | score |
|---|---|---|
| v1 | baseline | 100.0 |
| v2 | avoid heap allocations | 112.7 |
Avoiding heap allocations makes ListDir() 12.7% faster. Not bad. As an added bonus, those casts
will fend off the occasional frontend developer who accidentally wanders into the codebase.
v3
opendir() is an expensive call whose performance is linear in the number of subdirectories in the
path because it needs to perform a lookup for every one of them. We can replace it with openat(),
which takes a file descriptor to the parent directory and a name of the subdirectory. Just a single
lookup, less CPU time. This optimization assumes that callers already have a descriptor to the
parent directory, which is indeed the case for gitstatusd, and is often the case in other
applications that traverse filesystem.
void ListDir(int parent_fd, const char* dirname, string& arena, vector<char*>& entries) { // +
entries.clear();
int dir_fd = openat(parent_fd, dirname, O_NOATIME | O_RDONLY | O_DIRECTORY | O_CLOEXEC); // +
if (dir_fd < 0) return; // +
if (DIR* dir = fdopendir(dir_fd)) {
arena.clear();
while (struct dirent* ent = (errno = 0, readdir(dir))) {
if (!Dots(ent->d_name)) {
entries.push_back(reinterpret_cast<char*>(arena.size()));
arena.append(ent->d_name, strlen(ent->d_name) + 1);
}
}
if (errno) entries.clear();
for (char*& p : entries) p = &arena[reinterpret_cast<size_t>(p)];
sort(entries.begin(), entries.end(),
[](const char* a, const char* b) { return strcmp(a, b) < 0; });
closedir(dir);
} else { // +
close(dir_fd); // +
} // +
}
This is worth about 3.5% in speed.
| version | optimization | score |
|---|---|---|
| v1 | baseline | 100.0 |
| v2 | avoid heap allocations | 112.7 |
| v3 | open directories with openat() |
116.2 |
v4
Copying file names to the arena isn't free but it doesn't seem like we can avoid it. Poking around
we can see that the POSIX API we are using is implemented on Linux on top of getdents64 system
call. Its documentation isn't very encouraging:
These are not the interfaces you are interested in. Look at
readdir(3) for the POSIX-conforming C library interface. This page
documents the bare kernel system call interfaces.
Note: There are no glibc wrappers for these system calls.
Hmm... The API looks like something we can take advantage of, so let's try it anyway.
First, we'll need a simple Arena class that can allocate 8KB blocks of memory.
class Arena {
public:
enum { kBlockSize = 8 << 10 };
char* Alloc() {
if (cur_ == blocks_.size()) blocks_.emplace_back(kBlockSize, 0);
return blocks_[cur_++].data();
}
void Clear() { cur_ = 0; }
private:
size_t cur_ = 0;
vector<string> blocks_;
};
Next, we need to define struct dirent64_t ourselves because there is no wrapper for the system
call we are about to use.
struct dirent64_t {
ino64_t d_ino;
off64_t d_off;
unsigned short d_reclen;
unsigned char d_type;
char d_name[];
};
Finally we can get to the implementation of ListDir().
void ListDir(int parent_fd, Arena& arena, vector<char*>& entries) { // +
entries.clear();
int dir_fd = openat(parent_fd, dirname, O_NOATIME | O_RDONLY | O_DIRECTORY | O_CLOEXEC);
if (dir_fd < 0) return;
arena.Clear(); // +
while (true) { // +
char* buf = arena.Alloc(); // +
int n = syscall(SYS_getdents64, dir_fd, buf, Arena::kBlockSize); // +
if (n <= 0) { // +
if (n) entries.clear(); // +
break; // +
} // +
for (int pos = 0; pos < n;) { // +
auto* ent = reinterpret_cast<dirent64_t*>(buf + pos); // +
if (!Dots(ent->d_name)) entries.push_back(ent->d_name); // +
pos += ent->d_reclen; // +
} // +
} // +
sort(entries.begin(), entries.end(),
[](const char* a, const char* b) { return strcmp(a, b) < 0; });
close(dir_fd);
}
How are we doing with this one?
| version | optimization | score |
|---|---|---|
| v1 | baseline | 100.0 |
| v2 | avoid heap allocations | 112.7 |
| v3 | open directories with openat() |
116.2 |
| v4 | call getdents64() directly |
137.8 |
Solid 20% speedup. Worth the trouble. Unfortunately, we now have just one reinterpret_cast instead
of two, and it's not nearly as scary-looking. Hopefully with the next iteration we can get back some
of that evil vibe of low-level code.
As a bonus, every element in entries has d_type at offset -1. This can be useful to the callers
that need to distinguish between regular files and directories (gitstatusd, in fact, needs this).
Note how ListDir() implements this feature at zero cost, as a lucky accident of dirent64_t
memory layout.
v5
The CPU profile of ListDir() reveals that almost all userspace CPU time is spent in strcmp().
Digging into the source code of std::sort() we can see that it uses Insertion Sort for short
collections. Our 32-element vector falls under the threshold. Insertion Sort makes O(N^2)
comparisons, hence a lot of CPU time in strcmp(). Switching to qsort() or
Timsort is of no use as all good sorting algorithms fall
back to Insertion Sort.
If we cannot make fewer comparisons, perhaps we can make each of them faster? strcmp() compares
characters one at a time. It cannot read ahead as it can be illegal to touch memory past the first
null byte. But we know that it's safe to read a few extra bytes past the end of d_name for every
entry except the last in the buffer. And since we own the buffer, we can overallocate it so that
reading past the end of the last entry is also safe.
Combining these ideas with the fact that file names on Linux are at most 255 bytes long, we can
invoke getdents64() like this:
int n = syscall(SYS_getdents64, dir_fd, buf, Arena::kBlockSize - 256);
And then compare entries like this:
[](const char* a, const char* b) { return memcmp(a, b, 255) < 0; }
This version doesn't give any speedup compared to the previous but it opens an avenue for another
optimization. The pointers we pass to memcmp() aren't aligned. To be more specific, their
numerical values are N * 8 + 3 for some N. When given such a pointer, memcmp() will check the
first 5 bytes one by one, and only then switch to comparing 8 bytes at a time. If we can handle the
first 5 bytes ourselves, we can pass aligned memory to memcmp() and take full advantage of its
vectorized loop.
Here's the implementation:
uint64_t Read64(const void* p) { // +
uint64_t x; // +
memcpy(&x, p, sizeof(x)); // +
return x; // +
} // +
void ByteSwap64(void* p) { // +
uint64_t x = __builtin_bswap64(Read64(p)); // +
memcpy(p, &x, sizeof(x)); // +
} // +
void ListDir(int parent_fd, Arena& arena, vector<char*>& entries) {
entries.clear();
int dir_fd = openat(parent_fd, dirname, O_NOATIME | O_RDONLY | O_DIRECTORY | O_CLOEXEC);
if (dir_fd < 0) return;
arena.Clear();
while (true) {
char* buf = arena.Alloc();
int n = syscall(SYS_getdents64, dir_fd, buf, Arena::kBlockSize - 256); // +
if (n <= 0) {
if (n) entries.clear();
break;
}
for (int pos = 0; pos < n;) {
auto* ent = reinterpret_cast<dirent64_t*>(buf + pos);
if (!Dots(ent->d_name)) {
ByteSwap64(ent->d_name); // +
entries.push_back(ent->d_name);
}
pos += ent->d_reclen;
}
}
sort(entries.begin(), entries.end(), [](const char* a, const char* b) {
uint64_t x = Read64(a); // +
uint64_t y = Read64(b); // +
return x < y || (x == y && a != b && memcmp(a + 5, b + 5, 256) < 0); // +
});
for (char* p : entries) ByteSwap64(p); // +
close(dir_fd);
}
This is for Little Endian architecture. Big Endian doesn't need ByteSwap64(), so it'll be a bit
faster.
| version | optimization | score |
|---|---|---|
| v1 | baseline | 100.0 |
| v2 | avoid heap allocations | 112.7 |
| v3 | open directories with openat() |
116.2 |
| v4 | call getdents64() directly |
137.8 |
| v5 | hand-optimize strcmp() |
143.3 |
Fast and respectably arcane.
Conclusion
Through a series of incremental improvements we've sped up directory listing by 43.3% compared to a naive implementation (v1) and 27.2% compared to a reasonable implementation that a seasoned C/C++ practitioner might write (v2).
However, these numbers are based on an artificial benchmark while the real judge is always the real
code. Our goal was to speed up gitstatusd. Benchmark was just a tool. Thankfully, the different
versions of ListDir() have the same comparative performance within gitstatusd as in the benchmark.
In truth, the directory chosen for the benchmark wasn't arbitrary. It was picked by sampling
gitstatusd when it runs on chromium git repository.
The final version of ListDir() spends 97% of its CPU time in the kernel. If we assume that it
makes the minimum possible number of system calls and these calls are optimal (true to the best
of my knowledge), it puts the upper bound on possible future performance improvements at just 3%.
There is almost nothing left in ListDir() to optimize.
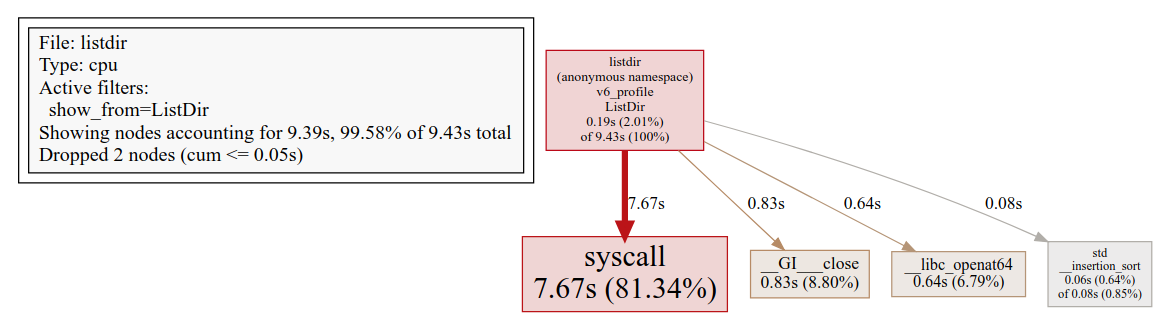
(The CPU profile was created with gperftools and rendered with pprof).